Stereo formats are widely known but struggle to provide a fully immersive surround sound experience. Surround sound is now used in a wide variety of scenarios, including music and film production, virtual visuals, gaming, and more, but it often requires extremely professional audio recording equipment to achieve it. Rapidly evolving AI and algorithms are about to change that.
We introduce an innovative upmixing methodology, comprised of two key modules, that turns a classic 2-channel track into a 5.1 surround sound format. Our approach utilizes a cutting-edge Deep Neural Network model capable of isolating four distinct sound elements – drums, bass, additional sounds, and vocals. Additionally, we make use of a PrimaryAmbient extraction algorithm to achieve 6-channel audio conversion.
This method delivers striking results across a range of audio including music and film, showing its versatile application. Our algorithms have been implemented in industrial applications and we may release many easy-to-use audio enhancement products on VanceAI soon. We are constantly updating it for better performance and more innovative features.
Features of AI Audio Upmix
AI Source Separation In One Click: AI audio upmix uses a variety of algorithms to analyze audio files, and with a single click, AI can help you accurately separate audio tracks from various types of movies or music, while ensuring the clarity of each individual track. Below is a very brief example of the results after audio enhancement, demonstrating our upmixing effect, please listen with headphones.
Auto Audio Upmix: After separating stereo sound into multiple channels, AI Audio Upmix simulates the approaches of professional audio producers, reorganizing these tracks and placing them in the correct positions to ensure audibility from all directions. This creates a sense of spatiality and depth that were only achievable previously with professional multi-channel recordings.
Jump to our Github project to learn about more audio upmixing example of the AI Audio Upmix tool (These examples are best demonstrated in a studio environment). If you want to learn more about audio upmix technology, keep reading our detailed research.
Research
Sound reproduction has been extensively researched, particularly in the mid-twentieth century, when the advent of surround sound revolutionized how we perceive and appreciate audio content [1].
Surround sound systems have evolved over time, driven by the expanding context of virtual reality, gaming, and binaural audio applications. This evolution began with monaural audio, progressed to stereo audio, and eventually led to the development of advanced multi-channel systems such as 5.1 (ITU 775 [2]) or 7.1, which are widely used in cinema and home theater systems. Figure 1 depicts a standard 5.1 audio arrangement, demonstrating the proper speaker placement and indicating how audio signals can be separated into Primary and Ambient sounds.
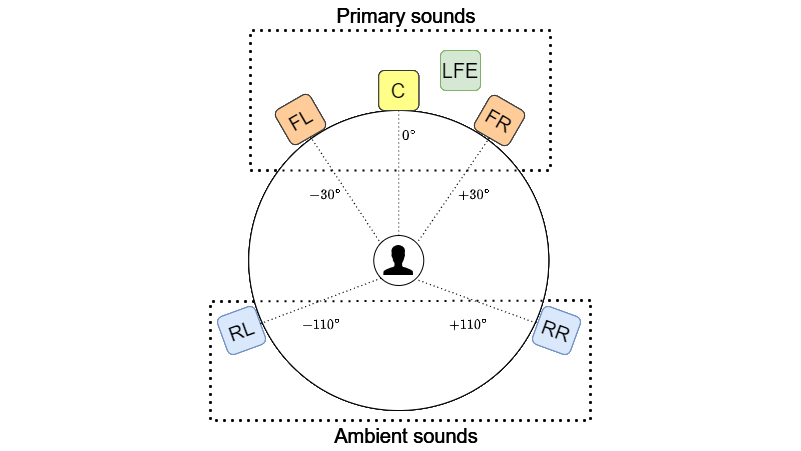
Notwithstanding the enhanced dimensionality brought by conventional two-dimensional surround sound which primarily engages listeners on a horizontal plane, the advent of diverse formats, notably Dolby Digital Plus, Dolby TrueHD, DTS-HD Master Audio, and Dolby Atmos, has amplified the number of audio channels. This expansion has subsequently produced a more immersive and convincing auditory experience. Object-oriented audio frameworks, typified by Dolby Atmos and DTS:X, augment this immersion by enabling dynamic positioning and relocation of sound objects within three-dimensional space, factoring in overhead channels to achieve 5.1.4 and 7.1.4 formats.
Prior to our research, we consulted a wealth of prior relevant studies, such as the development of several upmixing approaches in the past using the separation between Primary and Ambient sources [3, 4]. There are also some new methods that incorporate neural networks into the upmixing algorithm. Our approach has some similarities to previous research, but the main difference is that we integrated a Deep Learning Model [7].
Approach
A. Source separation module
With a focus on hybrid spectrogram/waveform domain source separation, our chosen source separation module is grounded in the Deep Neural Network advanced by D'effossez et al. [7]. This end-to-end model operates on 44s stereo audio samples, meticulously extracting four principal sources: drums, bass, other, and vocals. Our selection of this algorithm as the primary method for source extraction was influenced by its superior performance, which led to an acclaimed first place at Sony’s 2021 Music Demixing Challenge (MDX) [8].
However, we elected to implement only 2 pre-trained models to strike a well-rounded balance between speed and performance. In this refined arrangement, the output for each source is the average of the two models. This strategy was adopted primarily as a safeguard against potential artifacts and static noise, which may potentially arise from neural network learning on two different representations, namely time and frequency.
B. Primary-Ambient extraction module
In addition to the four sources procured via the source separation module, we utilized a Primary-Ambient extraction(PAE) algorithm. Notably, only the ambient sounds from the stereo input were exploited, given their critical contribution to generating a surround effect. This process necessitated the employment of the ADP algorithm [5], [6], a method predicated on the LMS adaptive filter, an estimator of central and surround sounds from stereo channels.

Each individual channel was subjected to the LMS algorithm implementation. Reflectively, the ADP algorithm, being fundamentally rooted in the LMS method, acts as a specific fine-tuning mechanism for adjusting the LMS coefficients.
Upmixing Strategy
We implemented and examined this algorithm on a home cinema system, aiding optimal distribution of sound. Fig. 2 visualizes the transition we achieved, transforming a 2-channel format into a vibrant 5.1 audio. The sequence of the channels is as follows: Front Left (FL), Front Right (FR), Center (C), Subwoofer (LFE), Rear Left (RL), and RearRight (RR).
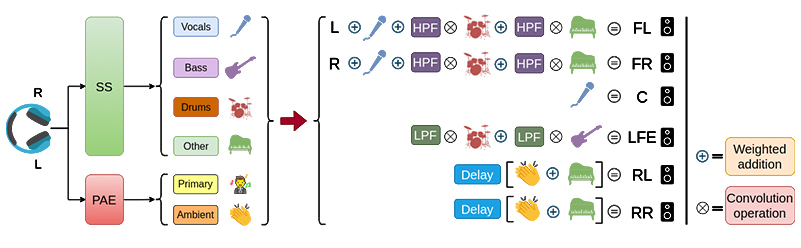
Recognizing the paramount importance of "voice", especially in cinematic audio content, our algorithm singularly allocates it to the Center speaker without any auxiliary processing. The Subwoofer or the Low Frequency Effects (LFE) speaker is typically utilized for specialized sounds which include low-frequency components, as exemplified by rumbling thunder, the tremors of an earthquake, resonant musical bass notes, and explosive sounds.
Our research found that for Front channels, an optimal blend of Vocals, Drums, Other sources, and the intrinsic left or right audio yields the most refined output. The Ambient component coupled with the Other source was employed in an unfiltered format to generate an effective Rear sound.
For a more detailed understanding of our audio mixing methodology, we invite you to refer to our scholarly paper.
Result
Many upmixing algorithms lack audio samples to validate their results, making it difficult to compare them objectively or subjectively. In our case, our sound engineer expert conducted extensive experiments to evaluate our algorithm and find the optimal solution for most scenarios. To make our research more rigorous, we believe that the Signal-to-Distortion Ratio (SDR) metric is the best current approximation for evaluating upmixing algorithms, as it is a good measure of the overall quality of an audio source. The specific measurement methods and results are available on paper. In conclusion, the experimental results meet our expectations and are well-suited for practical applications.
However, it is important to note that SDR only provides a possible estimate of how good an audio is compared to a reference. It does not measure all auditory components, and upmixing is a subjective process that cannot be fully evaluated objectively.
To address this, we also provide multiple audio samples for anyone to listen to and decide the quality of our upmixing method. These samples include both music and film audio resources and are available online. Our algorithms have been implemented in the VanceAI application with positive feedback, and you will be able to experience the completed functionality on AI Audio Upmixing soon.
For More Information
Read On MaDENN Github Project Read Full Paper
Authors
Marian Negru
Bogdan Moroșanu
Ana Neacșu
Dragoș Drăghicescu
Cristian Negrescu
Constantin Paleologu
Corneliu Burileanu
References
[1] F. Rumsey and T. McCormick, Sound and recording: an introduction. CRC Press, 2012.
[2] B. Series, “Multichannel stereophonic sound system with and without accompanying picture,” International Telecommunication Union Radio- communication Assembly, 2010.
[3] V. Pulkki, “Directional audio coding in spatial sound reproduction and stereo upmixing,” in Audio Engineering Society Conference: 28th International Conference: The Future of Audio Technology–Surround and Beyond. Audio Engineering Society, 2006.
[4] M. R. Bai and G.-Y. Shih, “Upmixing and downmixing two-channel stereo audio for consumer electronics,” IEEE Transactions on Consumer Electronics, vol. 53, no. 3, pp. 1011–1019, 2007.
[5] R. Irwan and R. M. Aarts, “Two-to-five channel sound processing,” Journal of the Audio Engineering Society, vol. 50, no. 11, pp. 914–926, 2002.
[6] C. J. Chun, Y. G. Kim, J. Y. Yang, and H. K. Kim, “Real-time conversion of stereo audio to 5.1 channel audio for providing realistic sounds,” International Journal of Signal Processing, Image Processing and Pattern Recognition, vol. 2, no. 4, pp. 85–94, 2009.
[7] A. De´fossez, “Hybrid spectrogram and waveform source separation,” arXiv preprint arXiv:2111.03600, 2021.
[8] Y. Mitsufuji, G. Fabbro, S. Uhlich, F.-R. St o¨ter, A. De´fossez, M. Kim, W. Choi, C.-Y. Yu, and K.-W. Cheuk, “Music demixing challenge 2021,” Frontiers in Signal Processing, vol. 1, p. 18, 2022.


